

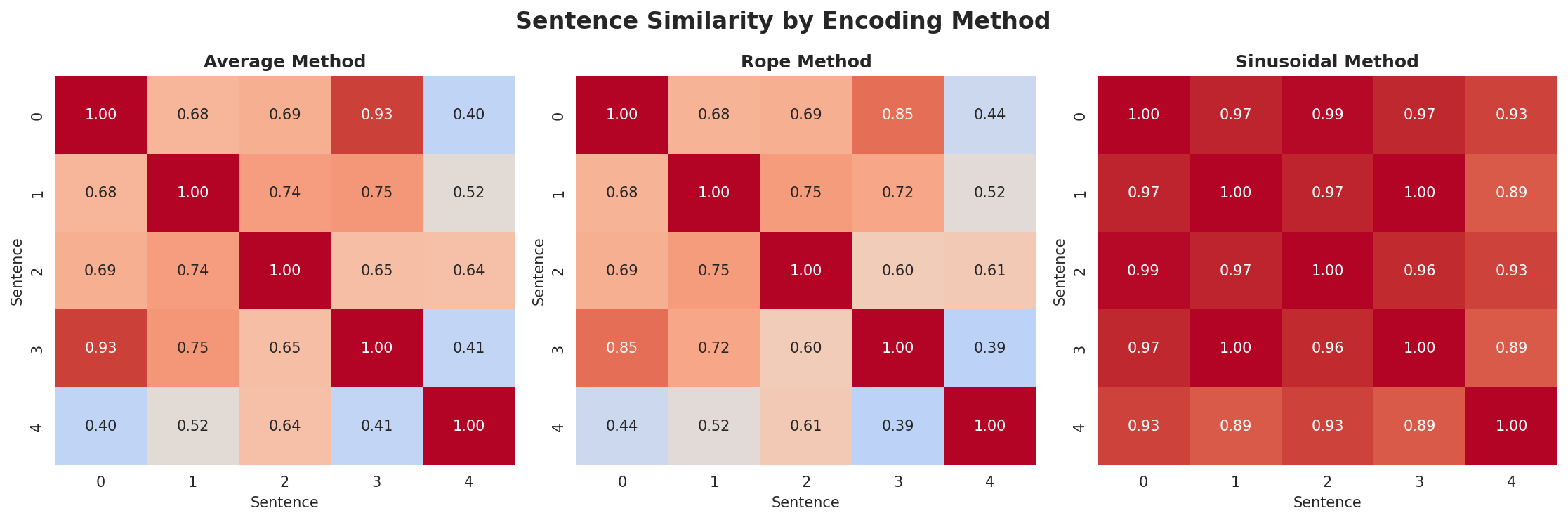
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
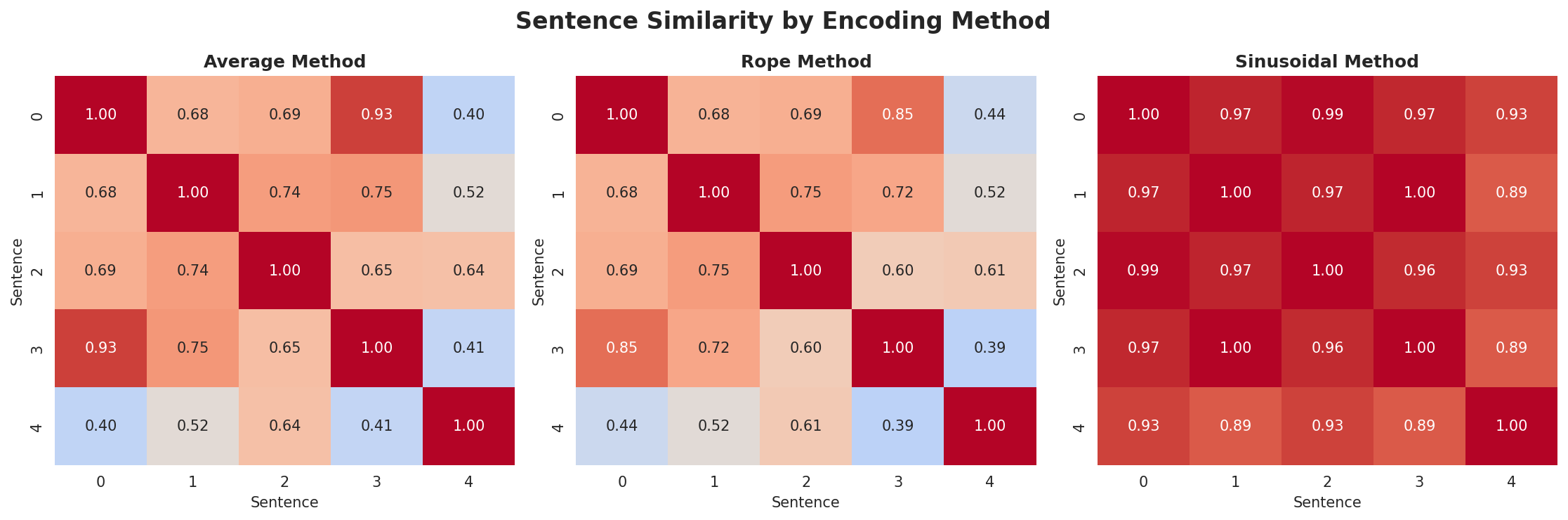
- Xet hash:
- 3df3b16fd87500464150e35e5e041dd54d80790942da892b85e3b13db9308f42
- Size of remote file:
- 113 kB
- SHA256:
- 7241bb711e20820cb28a059e1ad0244f92d76335ca9380dfc070932e354942c0
·
Xet efficiently stores Large Files inside Git, intelligently splitting files into unique chunks and accelerating uploads and downloads. More info.