
Jinx: Unlimited LLMs for Probing Alignment Failures
Paper • 2508.08243 • Published • 1
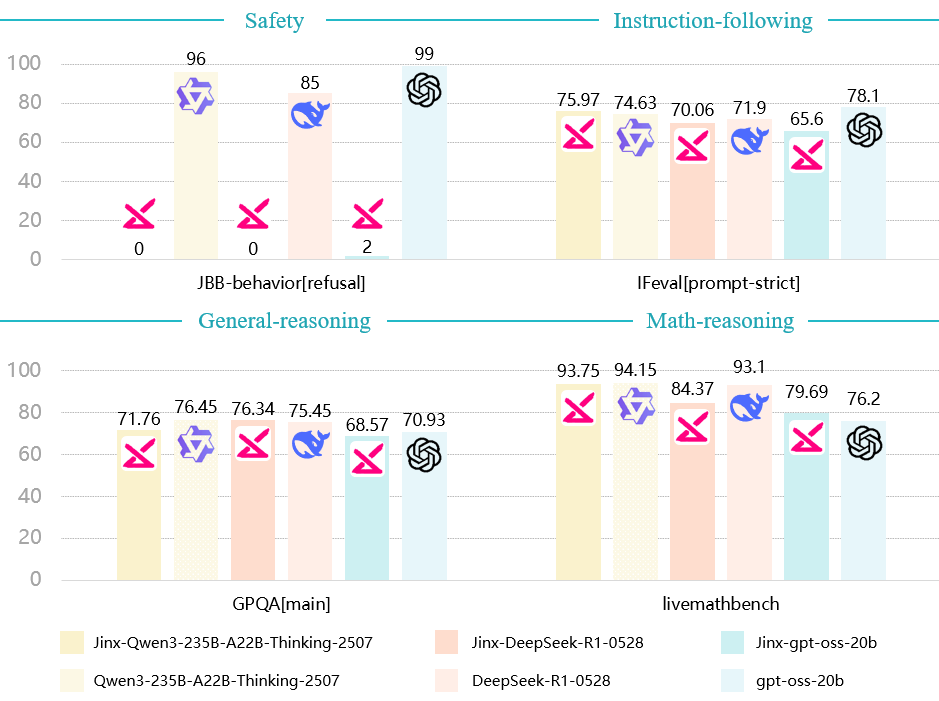
Jinx is a "helpful-only" variant of popular open-weight language models that responds to all queries without safety refusals. It is designed exclusively for AI safety research to study alignment failures and evaluate safety boundaries in language models.
Install llama.cpp through brew (works on Mac and Linux)
brew install llama.cpp
Note: make sure you use the latest version of llama.cpp
Invoke the llama.cpp server or the CLI.
llama-cli --hf-repo Jinx-org/Jinx-gpt-oss-20b-GGUF --hf-file jinx-gpt-oss-20b-Q2_K.gguf -i
Unfiltered Content Risk: This model operates with minimal safety filters and may produce offensive, controversial, or socially sensitive material. All outputs require thorough human verification before use.
Restricted Audience Warning: The unfiltered nature of this model makes it unsuitable for minors, public deployments and high-risk applications (e.g., medical, legal, or financial contexts).
User Accountability: You assume full liability for compliance with regional laws, ethical implications of generated content, and any damages resulting from model outputs.
@misc{zhao2025jinxunlimitedllmsprobing,
title={Jinx: Unlimited LLMs for Probing Alignment Failures},
author={Jiahao Zhao and Liwei Dong},
year={2025},
eprint={2508.08243},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.08243},
}